
UNIDAD I, II y III
TEMAS Y SUBTEMAS:
UNIDAD I. ANÁLISIS DE DATOS DE NEGOCIOS.
1.1 Definición de Estadística de Negocios.
La estadística de negocios es la ciencia que se encarga de recopilar, analizar, presentar e interpretar datos para facilitar la toma de decisiones en el ámbito de los negocios y la economía.
La estadística de negocios es una herramienta fundamental para las empresas, ya que permite:
Comprender el entorno comercial y económico
Mejorar la integración entre departamentos
Superar obstáculos y alcanzar metas
Evaluar el éxito de los negocios
Planificar en la alta dirección de las empresas
Controlar la ejecución de lo planificado
Investigar temas de la especialidad
Algunos ejemplos de estadísticas de negocios son:
Las estadísticas de ventas, que analizan las negociaciones y transacciones de los productos o servicios de la empresa
Las estadísticas de marketing, que miden el éxito de las campañas de marketing
La estadística del comercio exterior, que proporciona información sobre el intercambio comercial de mercancías
1.2 Estadística Descriptiva e Inferencia Estadística.
La estadística descriptiva y la estadística inferencial son dos ramas de la estadística que se utilizan para tomar decisiones basadas en datos:
Estadística descriptiva
Se encarga de resumir y describir los datos que ya se tienen. Se puede utilizar para una población o para una muestra. Para ello, se formulan recomendaciones para presentar los datos de manera clara y sencilla en cuadros, tablas, gráficos o figuras.
Estadística inferencial
Se encarga de hacer inferencias y generalizaciones sobre una población a partir de una muestra de datos. Se utiliza para modelar patrones en los datos y extraer conclusiones sobre la población.
La estadística inferencial es importante en el control de calidad industrial, ya que permite hacer afirmaciones sobre la fabricación total a partir de muestras extraídas.
La estadística inferencial se basa en cálculos probabilísticos, por lo que conlleva cierto margen de error.
1.3 Estadística Clásica y análisis bayesiano de decisiones.
La estadística bayesiana y la estadística clásica son dos enfoques diferentes para analizar datos estadísticos. La estadística bayesiana se basa en la probabilidad subjetiva y en la actualización de la evidencia, mientras que la estadística clásica se basa en la probabilidad frecuentista.
La estadística bayesiana se caracteriza por:
Considerar los parámetros de una población como cantidades aleatorias
Utilizar la distribución posterior para representar la incertidumbre sobre los parámetros
Tomar en cuenta las creencias previas, experiencias y criterio del investigador
Utilizar el Teorema de Bayes para calcular la distribución posterior de los parámetros.
La estadística bayesiana es una alternativa a la estadística clásica para resolver problemas como la estimación, el contraste de hipótesis y la predicción.
a estadística bayesiana es una alternativa a la estadística clásica para la solución de problemas típicos estadísticos como son: estimación, contraste de hipótesis y predicción. Ha generado un enorme interés en la última década y ha tenido una gran aceptación en mucha áreas de la investigación científica.
1.4 Variables Discretas y Variables Continúas.
Las variables discretas y las variables continuas son tipos de variables estadísticas que se diferencian en la cantidad de valores que pueden tomar:
Variables discretas
Son variables numéricas que pueden tomar un número finito de valores entre dos valores cualesquiera. Por ejemplo, el número de hijos de una pareja o el número de quejas de los clientes.
Variables continuas
Son variables numéricas que pueden tomar un número infinito de valores entre dos valores cualesquiera. Por ejemplo, la estatura de una persona o el tiempo que toma un atleta en recorrer 100 metros planos.
Las variables continuas pueden ser numérica o de fecha/hora. A diferencia de las variables discretas, las variables continuas nunca pueden ser medidas con exactitud. El valor observado depende en gran medida de la precisión de los instrumentos de medición.

Ejemplos de variables cuantitativas discretas:
El número de hijos de una familia.
La cantidad de dedos que tienes en la mano.
El número de faltas en un partido de fútbol.
Número de personas que llegan a un consultorio en una hora.
El número de árboles que hay en un parque.
El número de canales de televisión que tienes en casa.
Número de animales en una granja.
Cantidad de empleados que trabajan en una tienda.
Número de libros vendidos cada mes en Amazon.
Número de clientes que visitan un supermercado por día.
Ejemplos de variables cuantitativas continuas:
La estatura de tu mejor amigo.
El ancho de una pelota de fútbol.
Volumen de agua en una piscina.
El peso de una persona.
La velocidad a la que va a un tren.
Longitud en centímetros de un tenedor.
Tiempo que demora el delivery de Pizza Hut en entregar un pedido.
El volumen de cerveza en una jarra.
Peso de las vacas en una granja.
Tiempo que esperas al amor de tu vida.
Distancia que recorren los autos en una ciudad.
Velocidad a la que viaja un avión.
El diámetro de una esfera.
https://www.youtube.com/watch?v=fMW5S6JdMzg&t=2s
1.5 Obtención de Datos a través de Experimentos y Encuestas.
Son los datos que acompañan a los experimentos desde su planificación y preparación hasta la obtención de resultados. Los experimentos en muchos casos pueden repetirse para obtener los mismos datos sin embargo, su coste puede no ser rentable.
En cualquier campo de investigación, elegir las técnicas de recolección de datos más adecuadas es fundamental para cubrir el objetivo y propósito de una investigación.
Ya sea que estés realizando una investigación de tesis de grado o posgrado, o formes parte de un equipo de insights en una organización, debes tener muy claro el concepto y las diferentes técnicas de recolección de datos que existen.
Por ello, en este artículo hemos recopilado algunas de las más importantes para la investigación de mercados y la investigación social.
¿Qué son las técnicas de recolección de datos?
Las técnicas de recolección de datos son un conjunto de diferentes herramientas que permiten recopilar información de forma hábil y eficaz con fines de investigación y análisis.
Los proyectos de investigación suelen incluir la combinación de múltiples técnicas de recolección de datos para garantizar la validez y confiabilidad de una investigación.
El uso de múltiples técnicas y fuentes de recolección de datos refuerza la credibilidad de los resultados y permite incluir diferentes interpretaciones y significados en el análisis de los datos.
El término “técnicas de recolección de datos” suele utilizarse tanto para referirse a métodos de recolección de datos como a las diversas técnicas que forman parte de estos.
Inicio Investigación de mercado
Técnicas de recolección de datos: Qué son y cuáles existen
técnicas de recolección de datos
En cualquier campo de investigación, elegir las técnicas de recolección de datos más adecuadas es fundamental para cubrir el objetivo y propósito de una investigación.
Ya sea que estés realizando una investigación de tesis de grado o posgrado, o formes parte de un equipo de insights en una organización, debes tener muy claro el concepto y las diferentes técnicas de recolección de datos que existen.
¿Qué son las técnicas de recolección de datos?
Las técnicas de recolección de datos son un conjunto de diferentes herramientas que permiten recopilar información de forma hábil y eficaz con fines de investigación y análisis.
Los proyectos de investigación suelen incluir la combinación de múltiples técnicas de recolección de datos para garantizar la validez y confiabilidad de una investigación.
El uso de múltiples técnicas y fuentes de recolección de datos refuerza la credibilidad de los resultados y permite incluir diferentes interpretaciones y significados en el análisis de los datos.
El término “técnicas de recolección de datos” suele utilizarse tanto para referirse a métodos de recolección de datos como a las diversas técnicas que forman parte de estos.
Importancia del uso de técnicas de recolección de datos
Evaluar las técnicas que se tienen al alcance y su relevancia con respecto al objetivo de investigación es uno de los pasos más importantes de la recolección de datos.
La elección de las técnicas de recolección de datos más adecuadas es crucial para preservar la integridad de la investigación, independientemente del tema de estudio o del método de investigación preferido para definir los datos (cuantitativo, cualitativo).
Es menos probable que se produzcan errores cuando se utilizan las técnicas de recolección de datos adecuadas (ya sean nuevas, versiones actualizadas de las mismas o ya disponibles).
8 técnicas de recolección de datos más importantes
Existen múltiples técnicas de recolección de datos que puedes elegir como parte de la metodología de investigación que estés desarrollando. Entre las que destacan tanto en la investigación social, como en la investigación de mercados, están las siguientes:
Cuestionarios o encuestas
Los cuestionarios son una de las técnicas de recolección de datos más utilizadas, ya que pueden llevarse a cabo tanto física como digitalmente para recopilar datos cuantitativos a través de encuestas y datos cualitativos a través de entrevistas y encuestas cualitativas.
Los cuestionarios son una parte fundamental de las encuestas, y debido a que son baratos de crear y responder, son una opción muy accesible tanto para los investigadores como para sus corresponsales o encuestadores de campo.
Por lo general, los cuestionarios se utilizan para recoger respuestas sobre un acontecimiento o tema. Las respuestas recogidas pueden servir de base para la mejora de productos, matrices de toma de decisiones o estudios posteriores.
Observaciones
Las técnicas de recolección de datos más sencilla y directa parten de la observación, y pueden ser:
Observación cualitativa u observación cuantitativa.
Observación participante o no participante.
La forma más común de observación en el contexto de la recolección de datos consiste simplemente en observar los comportamientos o acciones de un sujeto en un entorno específico para comprenderlos y registrar lo observado.
En el mundo en línea de hoy en día, un ejemplo del acto de observación puede incluir ver a la gente interactuar con productos, sitios web y servicios en tiempo real.
Entrevista estructurada, semi-estructurada o no estructurada
Una entrevista se define exactamente como un encuentro formal entre dos individuos en el que el entrevistador hace preguntas al entrevistado para recabar información. Existen diferentes tipos de entrevista:
Estructurada: Es aquella que se compone de un cuestionario con una lógica diseñada especialmente para responderse de manera concreta.
Semi-estructurada: Es una técnica de recolección de datos en la cual se utiliza una serie de preguntas guía para orientar el tema de la conversación, pero no necesariamente se sigue al pie de la letra.
No estructurada: Es un tipo de entrevista en la cual no se sigue un cuestionario o guía de preguntas, sino que busca generar una conversación espontánea en torno al tema de interés. Generalmente se usa en la investigación exploratoria para identificar temas que puedan ser de valor para los sujetos, sin el sesgo de las teorías de investigación.
Grupo de discusión y focus groups
Otra técnica de recolección de datos es la realización de grupos de discusión, el cual busca propiciar una situación en la que se refleje el contexto social en el que se desarrollan las perspectivas y opiniones de las personas.
Un grupo de discusión es un tipo de conversación similar a una entrevista que tiene lugar en un grupo de seis a doce personas que comparten un interés, característica o necesidad común.
Las técnicas de los grupos de discusión o focus groups pueden ser entrevistas en grupo, grupos de expertos, grupos delphi, focus groups online, etc.
Seguimiento transaccional
El seguimiento de transacciones es una técnica de recolección de datos que se basa en las compras realizadas para obtener información.
Con cada compra realizada por un cliente, los investigadores y vendedores pueden acceder a los datos de sus sitios web, de un proveedor de servicios externo o de su sistema de punto de venta de comercio electrónico en tienda.
A partir de ahí, se pueden rastrear diferentes formas y cantidades de datos, lo que les permite crear mejores planes de marketing y productos, y dirigirse a los clientes ideales.
Seguimiento en redes sociales
El social listening o monitorización de redes sociales es una técnica de recolección de datos similar al seguimiento de transacciones.
Sin embargo, en lugar del historial de transacciones de un cliente, este tipo de técnica se centra en el seguimiento de su historial y huella en las redes sociales.
Muchas plataformas y empresas lo utilizan para hacer un seguimiento de la participación de los usuarios en diferentes publicaciones en línea y comprender mejor qué productos y servicios les interesan, así como qué consideran importante para ellos.
Panel de encuestas
Un panel de encuestas puede proporcionar estadísticas relacionadas con la tasa de respuesta, la tasa de finalización, los filtros basados en la demografía, las opciones de exportación y uso compartido, etc.
Una vez recopilados los datos, el software para encuestas puede generar varios tipos de informes y ejecutar algoritmos analíticos para descubrir información oculta.
Análisis textual o de contenido
El análisis de texto o de contenido es una técnica de recolección y análisis que se utiliza como parte de los métodos de recolección de datos secundarios.
Esta técnica permite investigar los cambios en los puntos de vista oficiales, institucionales u organizativos sobre un tema o área específicos, para documentar el contexto de ciertas prácticas o para investigar las experiencias y perspectivas de un grupo de individuos que, por ejemplo, han participado en una reflexión escrita.
1.6 Métodos de Muestréo Aleatorio.
El muestreo aleatorio es un método de selección de una muestra de una población mayor, en el que cada miembro de la población tiene la misma probabilidad de ser elegido. Este tipo de muestreo es probabilístico y se considera confiable y riguroso, ya que no está sujeto a sesgos que puedan comprometer los resultados.
Para realizar un muestreo aleatorio simple, se pueden seguir los siguientes pasos:
Definir la población que se estudiará
Determinar el tamaño de la muestra
Identificar a cada miembro de la población con un número único
Generar números aleatorios
Seleccionar los elementos de la población utilizando los números aleatorios
Registrar los elementos elegidos
Analizar los datos recolectados
Evaluar la muestra para asegurar que los resultados sean extrapolables a la población total
El muestreo aleatorio simple puede tener dos subtipos: con reemplazo y sin reemplazo. En el muestreo con reemplazo, el elemento seleccionado se devuelve y puede ser elegido de nuevo. En el muestreo sin reemplazo, el elemento seleccionado se retira de la población y no puede ser elegido de nuevo.
1.6.1 Utilización de Computadoras para generar números aleatorios.
Las computadoras generan números aleatorios mediante algoritmos que imitan la aleatoriedad, o mediante procesos físicos impredecibles:
Generadores de números pseudoaleatorios (PRNG)
Utilizan algoritmos deterministas y una semilla inicial para producir secuencias que parecen aleatorias. Por ejemplo, en Python se puede usar la función rand().
Generadores de números aleatorios de hardware (HRNG)
Se basan en procesos físicos impredecibles, como la desintegración radiactiva o el ruido atmosférico. Por ejemplo, el sitio Random.org utiliza ruido atmosférico.
Los números aleatorios se utilizan para: Análisis científicos, Juegos, Sorteos, Simular sistemas matemáticos y físicos complejos.
Algunos algoritmos PRNG son: El generador congruencial lineal, El método del cuadrado medio, El generador Lehmer, El método multiplicativo secuencial.
Para generar números aleatorios para criptografía, se debe usar un PRNG especializado
UNIDAD II. PRESENTACIONES ESTADÍSTICAS.
2.1 Distribuciones de Frecuencias.
Una distribución de frecuencias es una tabla que ordena los datos estadísticos y asigna a cada dato su frecuencia correspondiente. El objetivo de las distribuciones de frecuencias es facilitar la obtención de información de los datos.
En las distribuciones de frecuencias, las modalidades de la variable se disponen en las filas, mientras que en las columnas se coloca el número de ocurrencias por cada valor.
Algunos tipos de frecuencias son:
Frecuencia absoluta: Es el número de veces que aparece un valor estadístico.
Frecuencia relativa: Es la frecuencia absoluta dividida entre el número total de datos.
Frecuencia acumulada: Es la suma de las frecuencias absolutas de todos los valores inferiores o iguales al valor considerado.
Frecuencia relativa acumulada: Es el cociente entre la frecuencia acumulada de un determinado valor y el número total de datos.
Para calcular la tabla de distribución de frecuencias, se divide la frecuencia absoluta de cada valor entre el tamaño total de la muestra. El resultado se expresa como un decimal o un porcentaje.
Una distribución de frecuencia enumera las características de las columnas de los datos:
Inferencias acerca del tipo de datos de cada uno de los valores de la columna
Un tipo de datos describe el formato estructural de los datos en una columna. Las columnas que contienen datos numéricos, por ejemplo, son de tipo N (numérico), mientras que las que contienen datos alfabéticos son de tipo A (alfabético).
Inferencias acerca de la clase de datos de la columna
Una clase es una variable que categoriza una columna según el uso de los datos en la columna. Por ejemplo, si una columna contiene datos de tipo 10/04/07, se asigna la clase Fecha a la columna, porque 10/04/07 es una expresión para una fecha.
Cálculo de la longitud para cada uno de los valores de la columna
Muestra la longitud total de los valores de una columna.
Número de nulos en la columna
Muestra el número total de valores vacíos que contiene una columna.
Número de valores válidos y no válidos de la columna
Muestra si un valor se ha inferido como válido o como no válido.
Expresión de formato para cada uno de los valores de la columna
Una expresión de formato es un patrón que describe el tipo de datos de una columna de acuerdo con el tipo de columna. Por ejemplo, si una columna es de clase Fecha, puede asignarse una expresión de formato de tipo AAMMDD a la columna (año, mes y día).
El análisis también desarrolla estadísticas acerca de las columnas de los datos:
Recuento de cardinalidad de la columna
Un recuento de cardinalidad es el número total de valores distintos de una columna.
Porcentaje de cardinalidad de la columna
Un porcentaje de cardinalidad es el cálculo del número total de valores distintos de una columna dividido por el número total de valores de la misma columna.
Longitud mínima, máxima y media de los valores de la columna
Muestra la longitud media de los valores y luego calcula las longitudes mínima y máxima de los valores de la misma columna.
Distribución de los tipos de datos inferidos
Muestra una distribución de todos los tipos de datos que se han inferido durante el análisis.
Distribución de las expresiones de datos inferidas
Muestra una distribución de todas las expresiones de formato que se han inferido durante el análisis.
2.2 Intervalos de Clase.
Un intervalo de clase es el ancho numérico de una clase en una distribución, y se define como la diferencia entre el límite superior y el límite inferior de la clase.
En estadística, cada intervalo de clase tiene un límite inferior y un límite superior, que son los valores más pequeños y más grandes de la clase, respectivamente. El punto medio de la clase es el promedio de los límites inferior y superior.
Los intervalos de clase se pueden utilizar para dividir un rango de valores en categorías de clasificación, de modo que cada elemento de datos esté contenido en una categoría que no se superpone con otras.
Para calcular el tamaño de clase, se divide el rango entre el número de clases. Si al elaborar los intervalos algunos datos quedan fuera del número de clases, se debe agregar una clase más al final.
Para obtener la frecuencia de clase, se cuentan los datos que corresponden al intervalo de dicha clase en la tabla de datos ordenados.

2.3 Histográmas y Polígonos de Frecuencias.
El histograma y el polígono de frecuencias son gráficos que se utilizan para representar la distribución de frecuencias de datos agrupados. La principal diferencia entre ambos es que el polígono de frecuencias se crea a partir de un histograma:
Histograma
Es un gráfico que representa una variable en forma de barras, donde la superficie de cada barra es proporcional a la frecuencia de los valores representados. Se utiliza para ver cómo se distribuye un conjunto de datos o cómo se ha comportado una muestra.
Polígono de frecuencias
Es un gráfico que se crea uniendo con una línea los puntos medios de las columnas del histograma. Se utiliza para mostrar la frecuencia con la que cambia una variable o categoría.
Para construir un histograma se necesita una tabla de frecuencias. Los pasos para construir un histograma son:
Colocar los intervalos en el eje de abscisas (eje horizontal) de menor a mayor.
Representar las frecuencias absolutas de cada intervalo en el eje de ordenadas (eje vertical).
Dibujar barras rectangulares de anchura igual y proporcional al intervalo.
Dibujar las barras rectangulares adyacentes la una a la otra, pero sin que se intersequen.
El polígono de frecuencias es una herramienta gráfica que se emplea en las ciencias sociales y económicas para establecer comparaciones entre los resultados de un mismo proceso.

2.4 Curvas de Frecuencias.
Una curva de frecuencia es una representación gráfica de la distribución de un conjunto de datos. Es una versión suavizada de un histograma, que se utiliza para entender la distribución de probabilidad subyacente de un conjunto de datos.
Se construye utilizando líneas para unir los puntos medios de cada intervalo o clase. Las alturas de los puntos representan las frecuencias. Se puede crear una curva de frecuencia a partir del histograma o calculando los puntos medios de las clases a partir de la tabla de distribución de frecuencias. El punto medio de una clase se calcula sumando los valores de los límites superior e inferior de la clase y dividiendo la suma por 2.


2.5 Distribuciones de Frecuencias Acumuladas.
Una distribución de frecuencias acumuladas es una tabla que muestra la frecuencia acumulada de los valores o categorías hasta un punto determinado.
La frecuencia acumulada es la suma de las frecuencias absolutas de todos los valores menores o iguales al valor considerado.
Para calcular la frecuencia acumulada relativa se divide la frecuencia acumulada de un valor entre el número total de datos. El resultado se puede expresar en porcentaje.
Las distribuciones de frecuencias son tablas que organizan las modalidades de una variable en filas y el número de ocurrencias de cada valor en columnas. El objetivo de agrupar los datos en frecuencias es facilitar la obtención de la información que contienen.
A partir de las frecuencias acumuladas se pueden realizar diagramas integrales, que son gráficos crecientes.
Una distribuciòn de frecuencias relativas acumuladas muestra la proporción de elementos con valores menores que o iguales al limite superior de cada clase. Una distribución de frecuencias porcentuales acumuladas muestra la proporción de elementos con valores menores que o iguales al limite superior de cada clase.
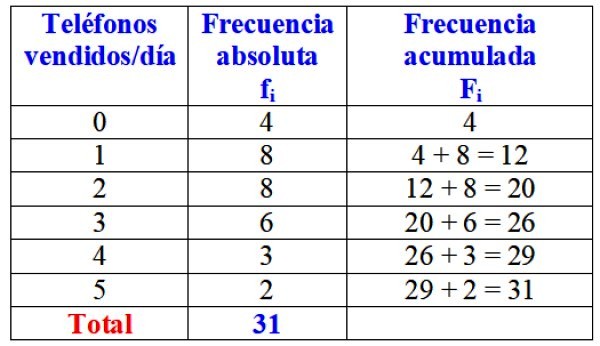
2.6 Distribuciones de Frecuencias Relativas.
Una distribución de frecuencias relativas es una tabla que muestra la proporción de elementos con valores menores o iguales al límite superior de cada clase. Para calcular las frecuencias relativas, se divide cada frecuencia entre el número total de datos. Las frecuencias relativas se pueden expresar como fracciones, decimales o porcentajes.
Tipo de frecuencia
Definición
Frecuencia absoluta
El número de veces que aparece un determinado valor estadístico
Frecuencia relativa
El número de veces que se repite un evento respecto al total, expresado en porcentajes
Frecuencia acumulada
La suma de las frecuencias absolutas de todos los valores inferiores o iguales al valor considerado
Frecuencia relativa acumulada
El cociente entre la frecuencia acumulada de un determinado valor y el número total de datos
2.7 Distribución de Frecuencias del Tipo “ y menor qué”.
En una distribución de frecuencias del tipo “y menor que”, las observaciones se acumulan e interpretan en relación con el límite superior de la clase.
Una distribución de frecuencias es una tabla que organiza los datos estadísticos, asignando a cada dato su frecuencia correspondiente. Las filas de la tabla contienen las modalidades de la variable, mientras que las columnas contienen el número de ocurrencias por cada valor.
Para calcular la frecuencia absoluta acumulada de un dato, se suma su frecuencia absoluta a las frecuencias absolutas de los datos que son menores que él.
La frecuencia absoluta es el número de veces que se repite un número en un conjunto de datos. La frecuencia relativa es la proporción que representa la frecuencia absoluta en relación con el total.

2.8 Gráficas de Barras y Gráficas de Línea.
Los gráficos de barras y los gráficos de línea son dos tipos de gráficos que se utilizan para representar datos de manera visual:
Gráficos de barras
Representan datos numéricos mediante barras verticales u horizontales, donde el tamaño de cada barra es proporcional al valor que representa. Son útiles para comparar cantidades o frecuencias.
Gráficos de línea
Representan cambios a lo largo del tiempo de una variable continua, uniendo una serie de puntos de datos mediante líneas. Son útiles para mostrar tendencias y relaciones, o para dar un panorama general de un intervalo.
Gráficos de barras
Gráficos de línea
Cómo se representan
Barras rectangulares verticales u horizontales
Puntos de datos unidos por líneas
Qué muestran
Comparaciones entre elementos individuales
Cambios a lo largo del tiempo de una variable continua
Cuándo son útiles
Para comparar cantidades o frecuencias
Para mostrar tendencias y relaciones
Ejes
Eje x para categorías discretas y eje y para valores
Eje x para escala de categoría o secuenciada y eje y para valor cuantitativo

2.9 Gráficas de Pastel.
¿Qué es una gráfica de pastel?
Una gráfica de pastel o gráfica circular es un tipo de representación para el análisis de datos estadísticos. Tiene la forma de un disco dividido en sectores, cuyas áreas son proporcionales a los porcentajes de los distintos componentes de la población estadística.
Cada valor del carácter estudiado corresponde a un sector. Las medidas de los ángulos de los sectores son proporcionales a los números representados (o a las frecuencias asociadas). La representación de números negativos es imposible con este tipo de diagrama.
Ejemplo de gráfica de pastel o circular
El nombre de esta gráfica se lo da su aspecto: Un pastel circular que ha sido cortado en varias rebanadas.
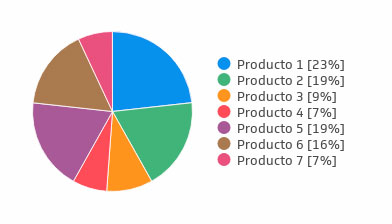
2.10 Resultados por Computadora.
Los resultados por computadora pueden referirse a los resultados de un examen de la vista, el rendimiento de una computadora o a los resultados de la Ingeniería Asistida por Computadora:
Examen de la vista por computadora
Es una prueba rápida que calcula la graduación del paciente con una computadora especial. El paciente debe ver un objeto en el interior del aparato y esperar el resultado.
Rendimiento de una computadora
Es la medida de la velocidad o resultado con que se realiza una tarea o proceso. El rendimiento de una computadora depende de la suma de sus componentes, sus softwares y la configuración de estos.
Resultados de la Ingeniería Asistida por Computadora
En la fase de procesamiento, la computadora realiza los cálculos y genera archivos con los resultados. Estos resultados se analizan en la fase de post procesamiento.
El análisis de datos cualitativos apoyado por una computadora no es otra cosa que el mismo análisis de datos cualitativos que se haría en textos escritos en el papel. Se trata simplemente de un medio para manejar los datos facilitando que el investigador realice su trabajo de análisis.
UNIDAD III. DESCRIPCIÓN DE DATOS DE NEGOCIOS: MEDIDAS DE POSICIÓN.
3.1 Medidas de Posición en conjuntos de Datos.
Las medidas de posición son estadísticas que permiten dividir un conjunto de datos en partes iguales y comprenderlos mejor. Se utilizan para caracterizar conjuntos de datos biométricos o psicológicos, como los resultados de un test de inteligencia.
Algunos ejemplos de medidas de posición son:
Mediana: Divide el conjunto de datos en dos partes iguales.
Cuartiles: Dividen el conjunto de datos en cuatro partes iguales.
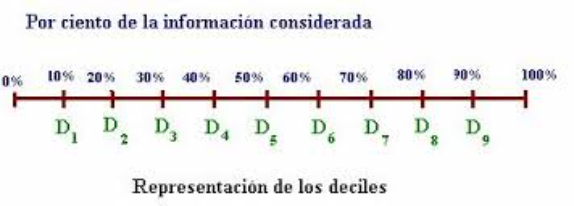
Deciles: Dividen el conjunto de datos en diez partes iguales.
Percentiles: Dividen el conjunto de datos en 100 partes iguales.
Las medidas de posición se pueden clasificar en dos tipos:
Medidas de tendencia central: Son la media, la mediana y la moda.
Medidas de posición no central: Son los cuartiles, los deciles y los percentiles.
Las medidas de posición proporcionan información resumida de la variable objeto de estudio.

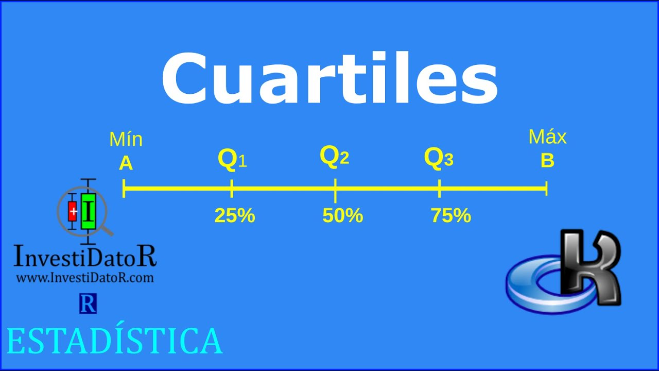

3.2 La Media Aritmética.
La media aritmética, también conocida como promedio, es un concepto matemático que se utiliza para resumir un conjunto de datos con un solo número. Se calcula sumando todos los valores del conjunto y dividiendo el resultado entre el número total de valores.
La media aritmética se utiliza en estadística, economía, antropología, historia y en casi todos los campos académicos. Por ejemplo, la renta per cápita es la media aritmética de la población de un país.
Por ejemplo, la media de 4, 1 y 7 es:
(4+1+7)/3=12/3=4)
La media aritmética no es una estadística robusta, ya que está muy influida por los valores atípicos. En distribuciones asimétricas, como la distribución de la renta, la media aritmética puede no ser representativa de la tendencia central. En estos casos, la mediana puede ser una mejor opción.


La media aritmética es un concepto matemático usado en estadística. También llamada promedio o simplemente media, se obtiene con la suma de un conjunto de valores dividida entre el número total de sumandos.
Además de en matemáticas y estadística, la media aritmética se utiliza con frecuencia en economía, antropología, historia y en casi todos los campos académicos en cierta medida. Por ejemplo, la renta per cápita es la renta media aritmética de la población de un país.
3.3 La Media Ponderada.
La media ponderada es una técnica matemática que calcula un promedio de un conjunto de números en el que no todos tienen la misma importancia. En este tipo de promedio, se asigna un peso o relevancia a cada número, lo que hace que algunos valores influyan más en el resultado final.
Para calcular la media ponderada, se multiplica cada valor por su peso, se suman los resultados y se divide el total entre la suma de los pesos.
En el ámbito financiero y contable, la relevancia de cada número puede estar determinada por su magnitud monetaria, su frecuencia, su riesgo asociado, o cualquier otro factor.
En Excel, se pueden utilizar las funciones SUMAPRODUCTO y suma para calcular un promedio ponderado.
3.4 La Mediana.
La mediana es un valor numérico que se encuentra en el centro de un conjunto de datos ordenados, y que divide a los datos en dos mitades iguales:
La mitad de los datos son mayores que la mediana.
La mitad de los datos son menores que la mediana.
La mediana se calcula de la siguiente manera:
Ordenar los datos de menor a mayor.
Localizar el número que se encuentra en la mitad de todos.
Si hay dos números en medio, se toma la media de esos dos números.
La mediana es una medida de tendencia central que se utiliza para distribuciones numéricas sesgadas.
La palabra mediana proviene del latín mediānus, que significa "del medio".
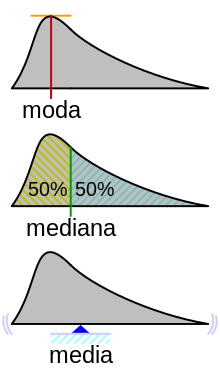
3.5 La Moda.
En estadística, la moda es el valor que aparece con mayor frecuencia en un conjunto de datos. Por ejemplo, si los datos son 2, 3, 3, 5, 7 y 10, la moda es 3.
La moda es una medida de tendencia central que se usa para comprender mejor el mundo que nos rodea. Es útil cuando hay muchos valores repetidos en un conjunto de datos.
Algunas características de la moda son:
No requiere valores numéricos y puede usarse con datos categóricos o discretos.
Puede haber un modo, conocido como unimodal, o varios modos, denominados bimodal o multimodal.
Se llama amodal cuando en un conglomerado no se repiten los valores.
Se representa por Mo.
Para calcular la moda, se debe descubrir el dato que más se repite en un conjunto de datos.
3.6 Relación entre la Media, la Mediana y la Moda.
La media, la mediana y la moda son medidas de tendencia central, es decir, valores numéricos que se utilizan para localizar la parte central de un conjunto de datos. La relación entre estas tres medidas es la siguiente:
Media
Es el resultado de repartir el total de los datos entre los individuos de la muestra. Se calcula sumando todos los datos y dividiendo el resultado entre la cantidad de datos.
Mediana
Es el valor que se encuentra en el centro de una secuencia ordenada de datos. Se calcula ordenando los datos de menor a mayor y eligiendo el número que se encuentra en la mitad.
Moda
Es el valor que más se repite en un conjunto de datos. Se calcula identificando el dato que más veces aparece.
La relación entre la media, la mediana y la moda también se puede observar en el tipo de distribución de los datos:
Si la media, la mediana y la moda son iguales, la distribución es simétrica.
Si la media es mayor que la mediana, la distribución es asimétrica con cola a la derecha.
Si la media es menor que la mediana, la distribución es asimétrica con cola a la izquierda.
En poblaciones con datos muy bajos o muy altos, se recomienda utilizar la mediana o la moda, ya que la media se ve afectada por los valores extremos.
3.7 Cuartiles, Deciles y Porcentajes.
Los cuartiles, deciles y percentiles son medidas de posición que dividen un conjunto de datos en partes iguales:
Cuartiles
Dividen la distribución en cuatro partes iguales. El primer cuartil (Q1) es la mediana de la primera mitad de los valores, el segundo cuartil (Q2) es la mediana de la serie y el tercer cuartil (Q3) es la mediana de la segunda mitad de los valores.
Deciles
Dividen la distribución en diez partes iguales. El decil 9 (D9) es la puntuación que deja por debajo las nueve décimas partes de la distribución.
Percentiles
Dividen la distribución en cien partes iguales. Un percentil es un porcentaje de valores que se encuentran por encima de un valor especificado. Por ejemplo, si el puntaje de una prueba está dentro del percentil 70, significa que la persona obtuvo un puntaje superior al 70% de las personas que realizaron la prueba.
3.8 La Media Aritmética para datos Agrupados.
Para calcular la media aritmética de datos agrupados en intervalos, se debe multiplicar la marca de clase por su frecuencia absoluta en cada intervalo y luego dividir la suma obtenida por el total de datos.
La media aritmética, también conocida como promedio, es una medida de tendencia central que se obtiene sumando todos los números de un conjunto de datos y dividiendo el resultado entre el número de valores.
La media se utiliza para distribuciones normales de números con una cantidad baja de valores atípicos.
3.9 La Mediana para datos agrupados.
La mediana para datos agrupados se calcula de la siguiente manera:
Dividir el número de datos entre 2 para encontrar la posición de la mediana.
Buscar la mediana en la frecuencia absoluta acumulada.
Si la mediana no está, buscar el número que sigue después del resultado obtenido en el paso 1.
La mediana es el número intermedio de un grupo de números, es decir, la mitad de los números son mayores que la mediana y la mitad son menores.
Para calcular la mediana de datos no agrupados, se ordenan los números de menor a mayor y se elige el número que se encuentra en la mitad.
En el caso de los datos agrupados, se utilizan intervalos de la misma amplitud, llamados clases, para agrupar los valores. A cada clase se le asigna su frecuencia correspondiente.
3.10 La Moda para datos agrupados.
En estadística, la moda es el valor que se repite con mayor frecuencia en un conjunto de datos, y se puede aplicar tanto a datos agrupados como no agrupados.
En el caso de los datos agrupados, si hay dos modas, se presentan en forma de una columna. Si hay tres modas, se trata de una distribución trimodal.
La moda es una de las medidas de tendencia central para datos no agrupados, y sirve para identificar cuando un dato aparece de forma continua o durante un periodo de tiempo determinado.
Un ejemplo de moda es el número 3, que es la moda del conjunto de números 2, 3, 3, 5, 7 y 10.
3.11 Cuartiles, Deciles y Porcentajes para datos agrupados.
Los cuartiles, deciles y percentiles son valores que dividen un conjunto de datos en partes iguales:
Cuartiles: Dividen la distribución en cuatro partes iguales.
El primer cuartil (Q1) separa el 25% inferior de los datos, el segundo cuartil (Q2) divide los datos en dos mitades y el tercer cuartil (Q3) separa el 75% inferior de los datos del 25% superior.
Deciles: Dividen la distribución en diez partes iguales. Se utilizan para definir sectores socioeconómicos según el ingreso per cápita familiar.
Percentiles: Dividen la distribución en cien partes iguales.
Para calcular los cuartiles, se puede seguir el siguiente procedimiento:
Contar el número de observaciones en el conjunto de datos (n).
Ordenar las observaciones de menor a mayor.
Calcular n * (1 / 4) para encontrar el primer cuartil.
Calcular n * (2 / 4) para encontrar el segundo cuartil.
Calcular n * (3 / 4) para encontrar el tercer cuartil.
3.12 Resultados por Computadora.